| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Режим быстрого страничного доступа
Режим быстрого страничного доступа (FPM – Fast Page Mode) представляет собой модификацию стандартного страничного режима. Основное отличие заключается в способе занесения новой информации в регистр адреса столбца. Полный адрес (строки и столбца) передается только при первом обращении к строке. Активизация буферного регистра адреса столбца производится не по сигналу CAS, а по заднему фронту сигнала RAS. Сигнал RAS остается активным на протяжении всего страничного цикла и позволяет заносить в регистр адреса столбца новую информацию не по спадающему фронту CAS, а как только адрес на входе микросхемы стабилизируется, т.е. практически по переднему фронту сигнала CAS. В целом же потери времени сокращаются на два такта, которые ранее требовались для передачи адреса каждой строки и сигнала RAS. Реальный выигрыш, однако, наблюдается лишь при передаче блоков данных, хранящихся в одной и той же строке микросхемы. Если же программа часто обращается к разным областям памяти, переходя с одной строки микросхемы на другую, преимущества метода теряются. Тем не менее, режим FPM нашел широкое применение в современных микросхемах динамических ОЗУ. Режим удвоенной скорости Важность режима удвоенной скорости передачи данных (DDR – Double Data Rate) трудно переоценить. Суть данного метода заключается в передаче данных по обоим фронтам импульса синхронизации, т.е. дважды за один такт. Тем самым пропускная способность системы памяти увеличивается в два раза. Групповой (пакетный) режим Данный режим (Burst Mode) является сочетанием блочного и страничного подходов. Разрядность ячейки памяти, как правило, равна одному байту, при этом ширина шины данных составляет не менее четырех байт. Одно обращение к памяти требует последовательного доступа к четырем смежным ячейкам – пакету. При реализации группового режима адрес столбца заносится в микросхему только для первой ячейки пакета, а переход к очередному столбцу производится уже внутри микросхемы. Это позволяет для каждого пакета исключить три из четырех операций занесения адреса столбца и тем самым еще более сократить среднее время доступа.
Структурные методы повышения быстродействия ОП Методыданной группы направлены на повышение быстродействия ОП за счет оптимизации структурной организации ОЗУ, состоящего из множества микросхем. Помимо повышения быстродействия ОП, с помощью структурных методов добиваются увеличения разрядности ОП и, как следствие, - повышения ее емкости. К структурным методам относятся: · блочная организация ОП; · расслоение ОП (чередование адресов); · пакетная обработка множества доступов к ОП; · конвейерная обработка множества доступов к ОП;
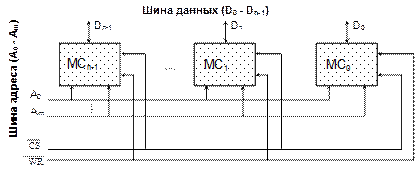
Блочная организация ОП Как правило, микросхемы ОЗУ (МС ОЗУ) имеют ограниченные как емкость, так и количество электрических входов, т.е. разрядность. Снять эти ограничения можно за счет объединения микросхем ОЗУ в модули памяти. Объем памяти модуляполучается равным сумме емкостей микросхем ОЗУ, а увеличение разрядности достигается за счет объединения адресных входов объединенных микросхем (рис. 3.3). Информационные входы и выходы микросхем являются входами и выходами модуля памяти увеличенной разрядности. Заметим, что модулем можно считать и единственную микросхему, если она уже имеет нужную разрядность. Один или несколько модулей образуютбанк памяти.
Рис. 3.3. Увеличение разрядности памяти
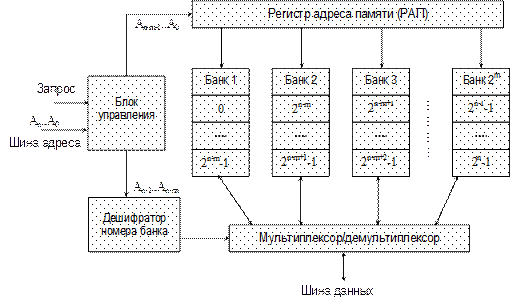
Для получения требуемой емкости ОП нужно определенным образом объединить несколько банков памяти меньшей емкости. В общем случае основная память ЭВМ практически всегда имеет блочную структуру, т.е. содержит несколько банков. При использовании блочной памяти, состоящей из N банков, адрес ячейки Aпреобразуется в пару (b, w), где b– номер банка, w – адрес ячейки внутри банка. Могут быть применены три схемы распределения разрядов адреса A между b и w: · блочная: номер банка b определяется по старшим разрядам адреса A; · циклическая: b = A mod N, w = · блочно-циклическая: комбинация двух первых схем. Пусть необходимо организовать n-разрядную ОП (рис. 3.4), состоящую из 2mбанков памяти по 2n-m слов в каждом. Адресное пространство разбивается на группы последовательных адресов, и каждая такая группа обеспечивается отдельным банком памяти. Для обращения к ОП используется n-разрядный адрес, n-mмладших разрядов которого (An-m-1 - A0) поступают параллельно на все банки памяти и выбирают в каждом из них одну ячейку. Старшие m разрядов адреса (An‑1 – An-m) содержат номер банка. Выбор банка обеспечивается либо с помощью дешифратора номера банка памяти, либо путем мультиплексирования информации.
Рис. 3.4. Блочная организация памяти В функциональном отношении такая память может рассматриваться как единое ОЗУ, емкость которого равна суммарной емкости составляющих, а быстродействие – быстродействию одного банка. Как видим, блочная организация непосредственно не увеличивает быстродействие ОП, однако без подобной организации невозможно применение остальных структурных методов. Расслоение памяти Наличие в системе множества банков памяти позволяет использовать потенциальный параллелизм, заложенный в блочной организации. Очевидно, что в каждый момент времени обращение возможно только к одному из слов каждого банка. Чтобы получить большую скорость доступа, нужно осуществлять одновременный доступ ко многим банкам памяти. Одна из общих методик, используемых для этого, называется расслоением памяти. В ее основе лежит так называемое чередование адресов (address interleaving), заключающееся в изменении системы распределения адресов между банками памяти. При расслоении банки памяти обычно упорядочиваются так, чтобы m последовательных адресов памяти A, A+1, A+2, ..., A+m-1 приходились на m различных банков. Соответствие некоторого адреса ОП A и адреса b внутри банка с номером N определяется соотношением
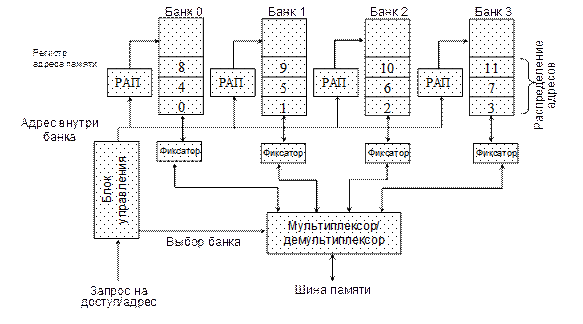
где m– общее число банков памяти. Распределение адресов между m банками памяти называется m-кратным чередованием адресов памяти, соответственно, память, состоящая из m банков с распределенными адресами, называется памятью с m-кратным чередованием адресов. Заметим, что число m является обычно степенью 2. Используя m-кратное чередование адресов, можно достичь в m раз большей скорости доступа к памяти в целом по сравнению с доступом к отдельному ее банку, если обеспечить при каждом доступе обращение к данным в каждом из банков. Ниже будут рассмотрены способы реализации таких расслоенных структур. Такие системы оптимизируют обращения по последовательным адресам памяти, что является характерным при подкачке информации в кэш-память при чтении, а также при записи, в случае использования кэш-памятью механизмов обратного копирования. Однако, если требуется доступ к непоследовательно расположенным словам памяти, производительность расслоенной памяти может несколько снижаться.
Рис. 3.5. Реализация памяти с 4-кратным чередованием адресов На рис. 3.5 изображена система с 4-кратным чередованием адресов памяти. Блок управления вычисляет выражение (3.3), определяя по адресу ОП номер банка памяти и адрес слова внутри банка. Последний передается регистрамадреса памяти (РАП) для выборки слова из банка. Из каждого банка памяти слово считывается в регистр-фиксатор данных. Выбор того или иного фиксатора осуществляется блоком управления по номеру банка. Через мультиплексор считанная информация поступает на шину памяти. Запись информации осуществляется аналогично, только в обратном порядке. Если система памяти разработана для поддержки множества независимых запросов (как это имеет место при работе с кэш-памятью, при реализации многопроцессорной и векторной обработки), эффективность системы будет в значительной степени зависеть от частоты поступления независимых запросов к разным банкам. Обращения по последовательным адресам хорошо обрабатываются традиционными схемами расслоенной памяти. Фактически в системе с m-кратным чередованием адресов доступ к памяти возможен в интервале 1/m цикла памяти. Однако, если в течение m циклов, следующих непрерывно друг за другом, запрашивается доступ к одному и тому же банку, то до окончания предыдущего доступа к этому банку запрос на следующий доступ будет ожидать обработки. Такая ситуация называется конфликтом по доступу. Одно из решений, используемое в больших ЭВМ и ВС для предотвращения конфликтов по доступу, заключается в том, чтобы статистически уменьшить вероятность подобных обращений путем значительного увеличения количества банков памяти. Например, в супер‑ЭВМ Cray Y-MP C90 используется 1024-кратное чередование адресов, причем вся память разбита на 8 секций по 8 подсекций по 16 банков памяти в каждой подсекции. Адреса идут с чередованием по каждому из данных параметров. При одновременном обращении к одной и той же секции возникает задержка в 1 такт, а при обращении к одной и той же подсекции одной секции задержка варьируется от 1 до 6 тактов. При выборке последовательно расположенных данных или при выборке с любым нечетным шагом конфликтов по доступу не возникает. Расслоение памяти обычно реализуется одним из двух способов – с помощью пакетной или конвейерной обработки множества запросов к памяти, хотя возможно и сочетание этих двух способов.
|
 ;
;