| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
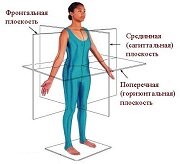
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
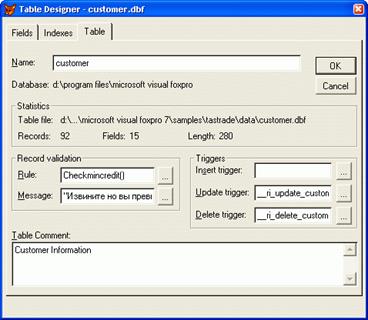
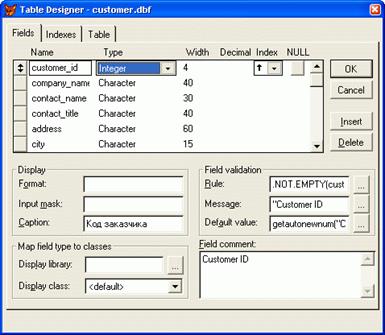
| Использование в Visual FoxProОткройте окно проекта. Выберите нужную таблицу и нажмите кнопку Modify (Модифицировать). Для определения свойств таблицы перейдите на вкладку Table (Таблица) конструктора таблиц. В поле ввода Insert trigger (Триггер добавления) задайте вызов функции AddNewCustomer (), которая добавляет новую запись в таблицу.
Для добавления новой хранимой процедуры AddNewCustomer откройте окно редактирования хранимых процедур и добавьте в него следующий текст: procedure AddNewCustomer nCurCdCustomer= icdCustomer SELECT NewCustomer APPEND BLANK REPLACE icdCustomer WITH ; nCurCdCustomer SELECT NewCustomer RETURN.T.
21. Методы поиска в базах данных. 1. Последовательный поиск: Записи просматриваются последовательно, для каждой проверяется выполнение условия поиска, если выполнено, то конец поиска. (в BuilderC++ Locate, в VFP – Locate). Достоинства: 1) универсальность, 2) простота. Недостаток: 1) низкое быстродействие, из-‐за последовательности просмотра. Последовательный поиск используется в последовательной и списковой организации. Блочный поиск Записи разбиты на блоки, упорядочены по значению. Выполняется последовательный просмотр блоков, для блока определяется возможность наличия записи, если может быть подходящая запись, то поиск внутри блока. В результате перебираем по блокам данные. Такая организация для страничной организации памяти. Бинарный поиск Записи упорядочиваются по ключу поиска, проверяется центральная запись, если подходит, то конец, если не подходит, то в соответствии со значением искомого и центральной записи отбрасывается какая-то половина таблицы, во второй проверяется середина. Если записи имеют фиксированное значение, то смещаемся на нужную запись, если же нефиксированная длина, то смотрим по меткам, то есть обращаемся в середину памяти и смещаемся далее до первой встретившейся метки. Достоинства: теоретически является самым быстрым поиском, практически быстродействие среднее из-‐за неэффективного использования считываемых данных. Данные читаются блоками, а внутри него берется только одно значение (на начальных шагах). Индексный поиск Индекс хранит описание логической последовательности записей по заданному ключу. Простейший вариант – последовательный индекс. Хранится последовательность пар – индекс ключа, адрес записи. Выигрываем потому, что данные пары имеют гораздо меньшее значение, следовательно, их можно хранить в оперативной памяти и, следовательно, ускорится поиск. Недостаток – низкое быстродействие. Для улучшения используют иерархические индексы. В основном строятся на основе бинарных деревьев и В+ деревья. Бинарное – дерево содержит индекс ключа и два указателя – левый – на код дерева с меньшими значениями ключа, правый – код дерева с большими значениями. Достоинства – простота построения дерева. Недостатки – низкая эффективность из‐за большого числа обращений к диску. Улучшения: 1) Можно использовать, когда данные исходные известны. 2) Физически располагать следующую запись после текущей, вторую в свободном пространстве, тогда за одно чтение читаются две записи. В+ дерево N -‐ого порядка – содержит N −1 значение и N указателей в одном узле, на верхних уровнях индекса это указатели на нижележащий уровень, на самом нижнем уровне – указатели на записи. Дерево строится снизу-вверх. Достоинство: 1) Малое число обращений к диску. 2) Уравновешенность ветвей. Недостатки: 1) Усложнение организации. Индексы могут быть неплотными. В неплотном индексе указатель нижнего уровня показывает не на запись, а на блок, где может находиться запись. Используется для индексной организации Хешированный поиск Используется для хешированной организации. Выполняется расчет адреса по значению искомого ключа Три шага: 1) нечисловое значение ключа пересчитывается в числовое. 2) хеширование числовых ключей, результат – набор числе с распределением близким к равномерному. 3) определение адресов в памяти. Недостаток – наличие коллизий – соответствие нескольким значениям ключа одного адреса. Основной способ разрешения коллизий - хранение перекрывающихся данных в виде списка в дополнительной области памяти.
22. Документальные базы данных. Основные понятия и определения. Информационно-поисковые системы в документальных БД. Документальными БД называются такие БД, которые содержат неструктурированные документы, различные тексты, картинки, звуковые файлы и т.д. Документальные БД должны сопровождаться поисковой системой, с помощью которой выдается список документов в той или иной степени, отвечающих условиям запроса. Поисковая система, предназначенная для отыскания документов, опирается на поисковый массив (ПМ). Поисковый массив такой ИПС состоит из поисковых образов документов (т.е. элементов, каждый из которых передает основное содержание документа) или из самих документов. В ответ на предъявляемый информационный запрос ИПС выдает некоторое множество документов (или адреса их хранения), содержащих искомую информацию. Принципиальной особенностью документальной системы является ее способность, с одной стороны, выдавать ненужные пользователю документы (например, где слово «Пушкин» употреблено в ином смысле, чем предполагалось), а с другой - не выдавать нужные (например, если автор употребил какой-то синоним или ошибся в написании). Документальная система должна уметь по контексту определять смысл того или иного термина, например, различать «ромашка» (растение), «ромашка» (тип печатающей головки принтера).
23. Документальные базы данных. Лингвистические банки данных. Словарь А.А. Зализняка. Под лингвистическими банками данных (ЛБД) понимаются представленные в электронной форме языковые источники (корпусы текстов) и лингвистические описания. Назначение лингвистических банков данных может различаться, так как часть ЛБД предназначена для автоматизации деятельности лингвистов и разработчиков прикладных систем, часть – для непосредственного использования в системах обработки текста и речи: автокорректорах, системах распознавания текста и речи, информационно-поисковых системах. Пользователь-человек часто может извлечь нужную ему информацию из ЛБД, встроенного в компьютерную систему обработки текстов. Однако компьютерная система обычно не может извлечь нужную для ее работы информацию непосредственно из ЛБД, ориентированного на человека. При использовании словарей в составе компьютерных систем обработки текстов ситуация иная. Самоочевидные для человека грамматические свойства слова, определяющие особенности его склонения/спряжения, должны быть тем или иным способом явно представлены в компьютерном словаре и в программах морфологического анализа и синтеза, позволяющих определять грамматические признаки словоформ текста и генерировать слова в требуемой форме. Как распределить знания о чрезвычайно сложных и запутанных правилах русского словоизменения между словарями и программными компонентами? Здесь возможны два решения: 1. в словаре описываются только словоизменительные признаки слов (тип и частные особенности склонения/спряжения), а работа по анализу и синтезу словоформ “поручается” программам морфологического компонента компьютерных систем; 2. в словаре приводятся все формы слов, каждой из которых сопоставлены все необходимые признаки (в частности, грамматические: число, падеж, лицо, время, наклонение и др.). Словарь Зализняка Одним из широкодоступных (и активно используемых) русскоязычных ЛБД является электронный вариант фундаментального «Грамматического словаря русского языка» А.А.Зализняка. Словарь Зализняка состоит из двух частей: «Грамматические сведения» (около 120 страниц) и собственно «Словарь» (около 740 страниц). В первой части представлена разработанная автором словаря с необычайной тщательностью оригинальная модель русского словоизменения (склонения и спряжения). Во второй – приведено около 100 тысяч слов, которым приписаны грамматические индексы, характеризующие тип их словоизменения и схему ударения. Слова упорядочены по концам, что естественно и удобно для грамматического словаря, поскольку слова со сходным грамматическим поведением (одинаковыми суффиксами и окончаниями) располагаются компактными группами. Пример. Словарная статья в словаре Зализняка состоит из заголовка (начальная форма слова) и словарной (грамматической) информации. Для некоторых слов даются также дополнительные сведения, необходимые для различения вариантов. Статьи с заголовками лев, стричь и прихожая выглядят так: лев мо 1*b (животное) |